
Going beyond the Claims of Accuracy in Automatic Speech Recognition
Many assessments use Automatic Speech Recognition (ASR) systems. Read our latest study by SHL Labs on the quality of transcriptions provided by ASR vendors.
Share
Speech transcription has a lot of significance in the talent assessment industry as the accuracy of many assessments, such as language proficiency tests and on-demand interviews, can be influenced by the quality of transcriptions. The global market for speech recognition is estimated to grow by 17.2% and reach $26.8 billion by 2025, which shows how big the speech recognition market is and how many options there are. It is critical that organizations are prepared for this increase in demand and are equipped to provide quality speech recognition systems.
What is speech transcription?
Speech transcription is a process of converting spoken words into written text. This can be done manually with the help of humans or automatically with artificial intelligence-based Automatic Speech Recognition (ASR) systems.
ASR is transforming how individuals and businesses communicate and get work done. It is used in a variety of scenarios and industries to improve business applications and streamline customer experiences, including meeting transcriptions, smart assistants, voice typing, customer care intelligence, and others. Although the use of ASR has its benefits, there have been some concerns raised regarding the quality of the transcriptions produced by these systems, specifically how to choose between vendors. This blog will address these concerns and provide results from a study comparing two of the most popular vendors of speech transcriptions.
How to get speech transcriptions
The speech transcriptions can be obtained from primarily two sources. The first category consists of vendors that offer speech transcriptions as an application programming interface (API) service. These consist of Google, Azure, Amazon, and others. The second category includes open-source libraries like DeepSpeech, Kaldi, Fairseq, etc. Vendor APIs are more accurate because they are continuously trained on a large amount of data and are simpler to integrate. However, the extensive use of APIs comes with a cost. Open-source libraries, on the other hand, are totally free and have no usage restrictions. However, more work is involved in training and maintaining the ASR models, especially if you try to use these libraries at scale.
Which one should you use, vendor APIs or open-source libraries? It depends. The decision on what source to use should be based on the target applications and the desired level of accuracy. For example, if you want to use speech transcriptions to build an application like a language proficiency test, then you should try to obtain transcriptions that are as accurate as possible. In this case, using the vendor APIs would be a better option.
However, even if you decide to use vendor APIs, how do you figure out which vendor API is the best for your case?
Although the use of ASR has its benefits, there have been some concerns raised regarding the quality of the transcriptions produced by these systems, specifically how to choose between vendors.
How to measure speech transcription accuracy
Transcription accuracy gives insight into the average percentage of errors a transcript (text) has per word count. For example, a transcription accuracy of 90% means that there are about 150 errors for every 1500 words.
The Word Error Rate (WER) is the most commonly used metric to assess transcription accuracy. It is calculated by adding the total number of transcription errors and dividing it by the total number of words in the source content, such as an audio file. The lower the WER, the more accurate the transcription.
The problem: selecting a vendor
As mentioned above, there are so many options for Automatic Speech Recognition tools in the market. It has become increasingly difficult to cut through the accuracy rates marketed by vendors. The main issue is that while these APIs perform exceptionally well on industry benchmark datasets, they fail to reproduce even close to the same results when put into application-specific real-world production environments.
Real-world applications include the representation of individuals from many diverse backgrounds that can influence how people speak. Furthermore, speech can also be affected by surrounding noise, recording devices, etc. As a result, it is critical to have an application-specific, diverse real-world speech dataset for a robust performance comparison.
To address this difficulty in selecting a vendor with ambiguous accuracy rates, we curated two datasets and evaluated the performance of the industry's two leading ASR vendors, Google and Azure. We measured how these two vendors would perform on real-world datasets.
Dataset 1
The first dataset included dialogue recordings from an assessment designed to measure a candidate's ability to perform successfully in an entry-level customer service role in a contact center. We had approximately 3000 recordings in total. The recordings had good coverage of multiple accents, including India, the United States, and the United Kingdom, as well as representation of different gender identities. Recordings were 10.1 seconds long on average, with a standard deviation of 8 seconds.
Each recording was transcribed by at least two human transcriptionists to determine the Word Error Rate (WER). Where the transcriptions did not match, calibration discussions were held. As a result, we got an extremely accurate dataset to measure.
Dataset 2
SHL's AI-powered English speaking, writing, listening, and comprehension evaluation, provided the second speech dataset. We had approximately 230,000 audios with good gender and accent coverage across the world. The audio files were 6.66 seconds long on average, with a standard deviation of 2.92 seconds. Since this dataset was so large, it was not possible to transcribe each audio file. As a result, we used the sentence that had to be spoken as a stand-in for the human transcription.
Speech accuracy comparison
We conducted a study comparing two popular vendor APIs, Google, and Azure. Speech transcription accuracy was compared using the Word Error Rate (WER) described above.
To obtain speech transcriptions from the supplied audio, we must provide a language code that contains the language + region/locale. To indicate different dialects, language codes typically include language tags and accent sub-tags. For example, the language code for English in the United States and India would be different. The vendor APIs have accent-dependent models for increased accuracy of different languages.
The accuracy comparison for both datasets is shown below:
Dataset 1
It is not always possible to know the accent of the audio. As a result, we conducted two studies.
- The audio is only transcribed with a US accent (Figure 1).
- The accent-dependent models are used to transcribe the audio (each audio is mapped to the closest accent) (Figure 2). This dataset has audio to accent mapping.
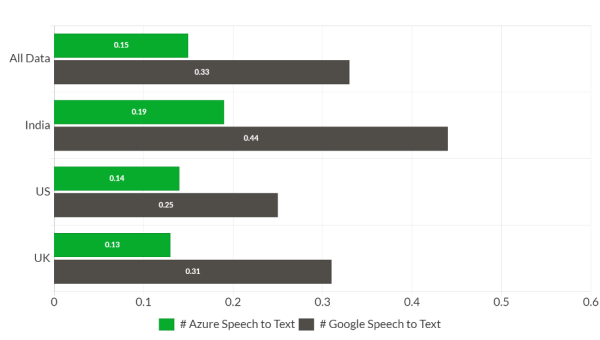
Figure 1: Word Error Rate (WER) comparison using only US accent
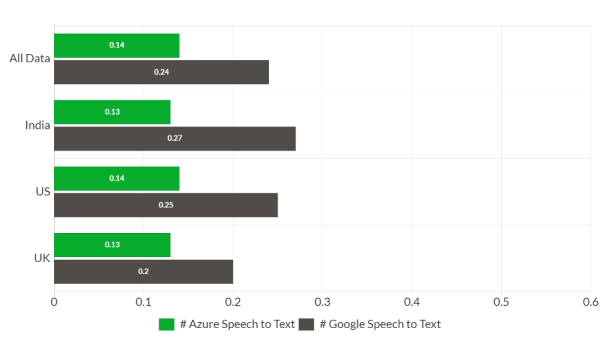
Figure 2: Word Error Rate (WER) comparison using accent-dependent models
Dataset 2
Assuming that we did not have audio-to-accent mapping here, so we only compared the transcription accuracy on the US accent (Figure 3).
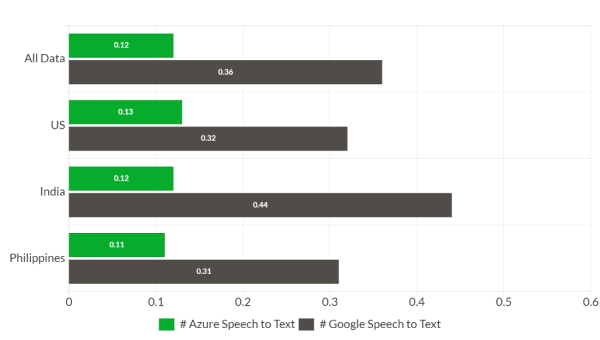
Figure 3: Word Error Rate (WER) using only US accent
The results
Looking at figures 1, 2, and 3, both vendors' transcription accuracy was significantly lower than human transcription accuracy, indicating that these APIs struggle when exposed to real-world application-specific datasets.
Even though the accuracy numbers are lower, Azure easily outperforms Google regardless of whether we know the accent of the audio. Overall, Azure is 36% more accurate than Google API in the case of the US accent model (figure 1). Azure is 27% more accurate in the case of the accent-dependent model (figure 2). Figures 1 and 2 show that even using only a US accent, Azure outperforms Google's accent-dependent models.
What do these results imply?
In this blog, we compared the accuracy of speech transcription on two popular ASR vendors. We investigated how ASR vendors fail to replicate accuracy numbers on diverse real-world datasets. Therefore, having real-world application-specific datasets is critical for conducting such studies and making informed decisions.
SHL conducts such studies on a regular basis to ensure that we use the best resources available and make the best hiring decisions possible for our customers. Stay tuned for more studies and innovations from the SHL Labs team!
Want to get high-quality hires? Use SHL’s accurate and objective assessment tools, such as SVAR and Smart Interview on Demand. Book a demo to learn more.








